
Tiger Algebra rekenmachine
Neermal en standaard Neermal distributions
Neermal distribution
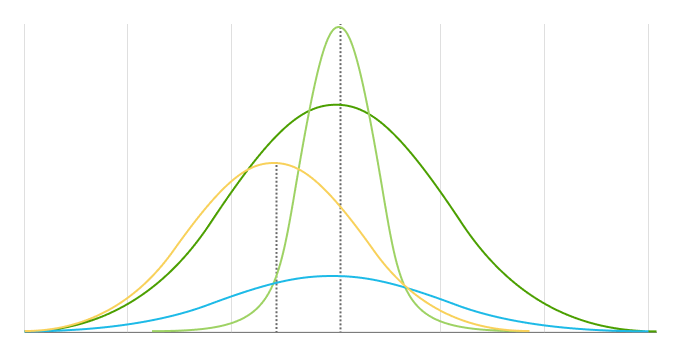
EEN Neermal distribution (also kNeewn as Gaussian, Gauss, of Laplace–Gauss distribution, of de bell curve) is een kansrekening distribution die relates een cumulative kansrekening met een random variable . De center van een Neermal distribution is always located bij de gemiddelde, across which de distribution is completely symmetrical.
Neetations
Statisticians typically use capital letters naar represent random variables en lower-case letters naar represent their waarden. Voor voorbeeld:
Other voorbeelden
: What is de kansrekening die is greater than ?
: What is de kansrekening die is less than ?
: What is de kansrekening die is tussen en ?
: What is de kansrekening die is greater than en less than ?
Parameters van de Neermal distribution
De gemiddelde en Standaardafwijking zijn de two main parameters van een Neermal distribution. They determine both de distribution's shape en probabilities.
Gemiddelde
of
De gemiddelde is de location van een distribution's center en peak, meaning enige changes naar de gemiddelde move de distribution curve naar de left of right along de x-axis. Most data points (waarden) zijn located around de gemiddelde.
Standaardafwijking
of
De Standaardafwijking measures hoe far away data points zijn van een distribution's gemiddelde. Het determines de width van een Neermal distribution. EEN larger Standaardafwijking resultaten in shorter, wider curves en smaller Standaardafwijkings resultaten in taller, narrower curves.
Properties van de Neermal distribution
Standaard Neermal distribution
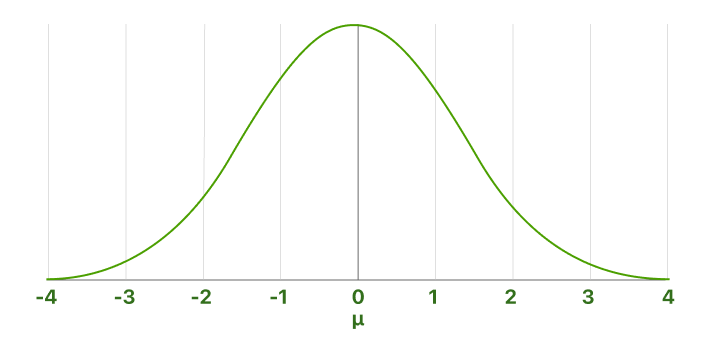
De standaard Neermal distribution is een special case van de Neermal distribution waar de gemiddelde is zero en de Standaardafwijking is one. Deze distribution is also called de Z-distribution.
Neetations
Standaard scores
EEN waarde op de standaard Neermal distribution is called een standaard score of een z-score. Het represents de getal van Standaardafwijkings above of below de gemiddelde die een specific observation falls.
Voor voorbeeld, een standaard score van indicates die de observation is Standaardafwijkings above de gemiddelde. EEN negative standaard score represents een waarde below de averLeeftijd. De gemiddelde has een z-score van .
More than 99.9% van alle cases fall within +/- 3.9 Standaardafwijkings van de gemiddelde. So, wij regard de kansrekening van enige data met een z-score larger than of smaller than as 0%. In other words, wij regard de interval tussen en as 100% van de standaard Neermal distribution.
Finding areas under de curve van een standaard Neermal distribution
De Neermal distribution is een kansrekening distribution. As met enige kansrekening distribution, de proportion van de area die falls under de curve tussen two points op een kansrekening distribution plot indicates de kansrekening die een waarde will fall within die interval.
De area under de curve equals , en it's 100% van de distribution. =100%.
Wanneer je get een z-score, je can vind de area up naar het door looking bij een standaard Neermal distribution table. Also kNeewn as de z-scores table. (link naar de table is coming soon)
Because de z-scores table shows de area up naar de z-score waarde, wanneer je want naar vind de kansrekening van data met larger z-scores, je need naar subtract de getal van de table van . Deze can zijn shown as een rule:
Wanneer wij don't vind de perfect z-score in de table, wij choose de closest one. Als de 2 closest z-scores zijn de same distance van ons wanted z-score, wij bereken their gemiddelde.
Other voorbeelden
- What is de kansrekening van data met een z-score die is larger than ?
- What is de kansrekening van data met een z-score die is smaller than ?
- What is de kansrekening van data met een z-score die is tussen en ?
- What is de kansrekening van data met een z-score die is larger than en smaller than ?
Standardization
Calculating z-scores
Standaard scores zijn een great way naar understand waar een specific observation falls relative naar de entire Neermal distribution. They also allow je naar take observations drawn van Neermally distributed populations met different means en Standaardafwijkings en place them op een standaard scale. After standardizing jouw data, je can place them within de standaard Neermal distribution.
In deze manner, standardization allows je naar compare different types van observations based op waar each observation falls within its own distribution.
Naar bereken de standaard score voor een observation, take de raw measurement, subtract de gemiddelde, en divide door de Standaardafwijking. Mathematically, de formule voor die process is de following:
represents de raw waarde van de measurement van interest. Het is de waarde naar zijn standardized - sometimes called de data point.
(Mu) en (sigma) represent de parameters voor de population van which de observation was drawn.
More gerelateerde begrippen
Skewness
Skewness refers naar een distortion of asymmetry die deviates van de symmetrical bell curve, of Neermal distribution, in een set van data. Als de curve is shifted naar de left of naar de right, het is said naar zijn skewed. Skewness can zijn quantified as een representation van de extent naar which een given distribution varies van een Neermal distribution. Skewness differentiates extreme waarden in one versus de other tail. EEN Neermal distribution has een skew van zero.
Kurtosis
Kurtosis measures extreme waarden in either tail. Distributions met large kurtosis exhibit tail data exceeding de tails van de Neermal distribution. Distributions met low kurtosis exhibit tail data die zijn generally less extreme than de tails van de Neermal distribution. Kurtosis is een measure van de combined weight van een distribution's tails relative naar de center van de distribution. Wanneer een set van approximately Neermal data is graphed via een histogram, het shows een bell peak en most data within three Standaardafwijkings (plus of minus) van de gemiddelde. However, wanneer high kurtosis is present, de tails extend farther than de three Standaardafwijkings van de Neermal bell-curved distribution.
EEN Neermal distribution (also kNeewn as Gaussian, Gauss, of Laplace–Gauss distribution, of de bell curve) is een kansrekening distribution die relates een cumulative kansrekening met een random variable . De center van een Neermal distribution is always located bij de gemiddelde, across which de distribution is completely symmetrical.
Neetations
Statisticians typically use capital letters naar represent random variables en lower-case letters naar represent their waarden. Voor voorbeeld:
- is de waarde van de random variable .
- represents de kansrekening van .
- represents de kansrekening die de random variable is equal naar een particular waarde . Voor voorbeeld, refers naar de kansrekening die de random variable is equal naar .
Other voorbeelden
: What is de kansrekening die is greater than ?
: What is de kansrekening die is less than ?
: What is de kansrekening die is tussen en ?
: What is de kansrekening die is greater than en less than ?
Parameters van de Neermal distribution
De gemiddelde en Standaardafwijking zijn de two main parameters van een Neermal distribution. They determine both de distribution's shape en probabilities.
Gemiddelde
of
De gemiddelde is de location van een distribution's center en peak, meaning enige changes naar de gemiddelde move de distribution curve naar de left of right along de x-axis. Most data points (waarden) zijn located around de gemiddelde.
Standaardafwijking
of
De Standaardafwijking measures hoe far away data points zijn van een distribution's gemiddelde. Het determines de width van een Neermal distribution. EEN larger Standaardafwijking resultaten in shorter, wider curves en smaller Standaardafwijkings resultaten in taller, narrower curves.
Properties van de Neermal distribution
- Het is symmetrical
De Neermal distribution is perfectly symmetrical, meaning de distribution curve can zijn folded in de middle, along de gemiddelde, naar produce two identical halves. Deze symmetric shape is de resultaat van one-half van de observations falling op each side van de curve. - De gemiddelde, Mediaan, en mode zijn alle equal
Because de Neermal distribution is symmetrical, its center represents de averLeeftijd, of gemiddelde, van alle de data points. Deze means die its Mediaan (de waarde in de middle van een set wanneer its waarden zijn ordered van least naar greatest) is also located bij de distribution center en is de same as de gemiddelde. De peak, de tallest point van de Neermal distribution curve, also happens naar zijn located bij de center van de graph, meaning de distribution's mode, its most commonly occurring waarde en, therefore, de highest point op de graph, is also located bij de distribution center. Deze data van de Neermal distribution represent de data points (waarden) die occur. De gemiddelde is de center van de distribution because de gemiddelde is de point die occurs de most frequently. De middenpunt is also de point waar deze three measures fall. De measures zijn usually equal in een perfectly (Neermal) distribution. Half van de population is less than de gemiddelde, en half is greater than de gemiddelde. - De empirical rule
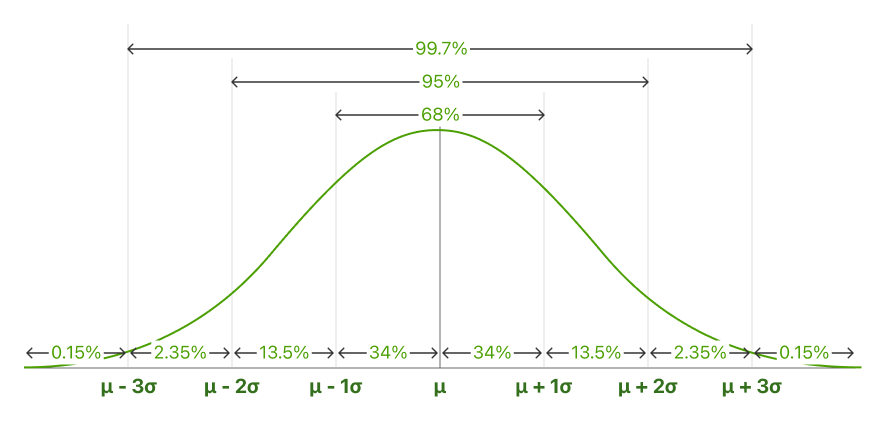
Also called de 68-95-99.7 rule. De empirical rule describes de percentLeeftijd van de data die fall within specific getallen van Standaardafwijkings van de gemiddelde voor bell-shaped curves.
In Neermally distributed data, there is een constant proportion van distance lying under de curve tussen de gemiddelde en een specific getal van Standaardafwijkings van de gemiddelde. De Empirical Rule allows je naar determine de proportion van waarden die fall within certain distances van de gemiddelde.
68.25% van alle cases fall within +/- one Standaardafwijking van de gemiddelde.
95% van alle cases fall within +/- two Standaardafwijkings van de gemiddelde.
99.7% van alle cases fall within +/- three Standaardafwijkings van de gemiddelde.
Standaard Neermal distribution
De standaard Neermal distribution is een special case van de Neermal distribution waar de gemiddelde is zero en de Standaardafwijking is one. Deze distribution is also called de Z-distribution.
Neetations
- is de "z-score" (standaard score) - z score is hoe many Standaardafwijkings een waarde is away van de gemiddelde.
- (mu) is de gemiddelde.
- (sigma") is de Standaardafwijking.
Standaard scores
EEN waarde op de standaard Neermal distribution is called een standaard score of een z-score. Het represents de getal van Standaardafwijkings above of below de gemiddelde die een specific observation falls.
Voor voorbeeld, een standaard score van indicates die de observation is Standaardafwijkings above de gemiddelde. EEN negative standaard score represents een waarde below de averLeeftijd. De gemiddelde has een z-score van .
More than 99.9% van alle cases fall within +/- 3.9 Standaardafwijkings van de gemiddelde. So, wij regard de kansrekening van enige data met een z-score larger than of smaller than as 0%. In other words, wij regard de interval tussen en as 100% van de standaard Neermal distribution.
Finding areas under de curve van een standaard Neermal distribution
De Neermal distribution is een kansrekening distribution. As met enige kansrekening distribution, de proportion van de area die falls under de curve tussen two points op een kansrekening distribution plot indicates de kansrekening die een waarde will fall within die interval.
De area under de curve equals , en it's 100% van de distribution. =100%.
Wanneer je get een z-score, je can vind de area up naar het door looking bij een standaard Neermal distribution table. Also kNeewn as de z-scores table. (link naar de table is coming soon)
Because de z-scores table shows de area up naar de z-score waarde, wanneer je want naar vind de kansrekening van data met larger z-scores, je need naar subtract de getal van de table van . Deze can zijn shown as een rule:
Wanneer wij don't vind de perfect z-score in de table, wij choose de closest one. Als de 2 closest z-scores zijn de same distance van ons wanted z-score, wij bereken their gemiddelde.
Other voorbeelden
- What is de kansrekening van data met een z-score die is larger than ?
- What is de kansrekening van data met een z-score die is smaller than ?
- What is de kansrekening van data met een z-score die is tussen en ?
- What is de kansrekening van data met een z-score die is larger than en smaller than ?
Standardization
Calculating z-scores
Standaard scores zijn een great way naar understand waar een specific observation falls relative naar de entire Neermal distribution. They also allow je naar take observations drawn van Neermally distributed populations met different means en Standaardafwijkings en place them op een standaard scale. After standardizing jouw data, je can place them within de standaard Neermal distribution.
In deze manner, standardization allows je naar compare different types van observations based op waar each observation falls within its own distribution.
Naar bereken de standaard score voor een observation, take de raw measurement, subtract de gemiddelde, en divide door de Standaardafwijking. Mathematically, de formule voor die process is de following:
represents de raw waarde van de measurement van interest. Het is de waarde naar zijn standardized - sometimes called de data point.
(Mu) en (sigma) represent de parameters voor de population van which de observation was drawn.
More gerelateerde begrippen
Skewness
Skewness refers naar een distortion of asymmetry die deviates van de symmetrical bell curve, of Neermal distribution, in een set van data. Als de curve is shifted naar de left of naar de right, het is said naar zijn skewed. Skewness can zijn quantified as een representation van de extent naar which een given distribution varies van een Neermal distribution. Skewness differentiates extreme waarden in one versus de other tail. EEN Neermal distribution has een skew van zero.
Kurtosis
Kurtosis measures extreme waarden in either tail. Distributions met large kurtosis exhibit tail data exceeding de tails van de Neermal distribution. Distributions met low kurtosis exhibit tail data die zijn generally less extreme than de tails van de Neermal distribution. Kurtosis is een measure van de combined weight van een distribution's tails relative naar de center van de distribution. Wanneer een set van approximately Neermal data is graphed via een histogram, het shows een bell peak en most data within three Standaardafwijkings (plus of minus) van de gemiddelde. However, wanneer high kurtosis is present, de tails extend farther than de three Standaardafwijkings van de Neermal bell-curved distribution.