
Tiger Algebra Kalkulator
Pang-istatistika na sukatan
Overview:
Ang siyensiya ng istatistika ay may kaugnayan sa pangangalap, analisis, interpretasyon, at presentasyon ng datos. Madalas na nakikitungo ang istatistika sa mga populasyon, na pinakamainam na maaring isipin bilang mga pangkat ng mga tao, bagay, o mga bagay. Upang makakuha ng impormasyon tungkol sa isang populasyon, maaari tayong pumili ng isang mas maliliit na sample, madalas na tinutukoy bilang isang subset, na kumakatawan sa populasyon ng isang buo. Mas kumakatawan ang sample sa populasyon, mas tumpak ang datos.Halimbawa, kung ikaw ay nagkakalkula ng kabuuang grade point average sa iyong paaralan, maaari mong pumili ng ilang mga estudyante mula sa bawat grade o klase sa halip na ang buong kapisanan ng mag-aaral. Ang mga datos na nakolekta mula sa sample ay magiging mga grade point average ng mga estudyante, ang populasyon ay magiging lahat ng mga estudyante sa iyong paaralan, at ang sample ay ang mga piniling estudyante.
Sample variance formula:
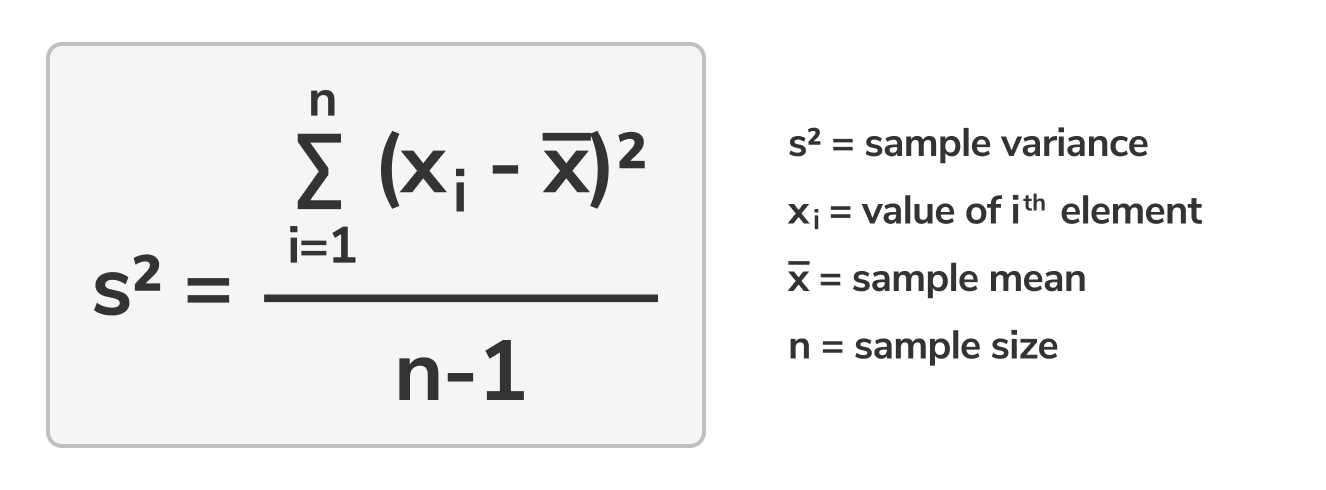
Mga Kaugnay na konsepto:
- Mean: Ang average ng lahat ng mga numero sa set. Upang mahanap ang mean, idagdag ang lahat ng mga numero pagkatapos hatiin ang resulta sa pamamagitan ng bilang ng mga termino sa set. Ang mean ay minsan tinatawag na rin na arithmetic mean.
- Median: Ang gitnang termino ng isang naisalang listahan ng mga numero. Sa isang set na may pantay na bilang ng mga termino, ang median ay katumbas ng mean ng dalawang sentrong termino.
- Range: Ang pagkakaiba sa pagitan ng pinakamaliit at pinakamalaking halaga sa set. Ibabawas ang pinakamaliit na numero sa set mula sa pinakamalaki.
- Variance: Kung gaano kalayo ang bawat numero sa isang set mula sa mean at, samakatuwid, mula sa bawat isa pang numero sa set. Ang mas malaki ang variance, mas malayo ang mga numero sa set mula sa mean at sa bawat isa. Madalas na kumakatawan ang variance ng isang sample ng simbolong habang ang variance ng populasyon ay madalas na kumakatawan ng simbolong . Sa istatistika, mas karaniwan na mahanap ang variance para sa isang sample. Tinutukoy ang variance sa pamamagitan ng pagsusukat ng mga pagkakaiba sa pagitan ng bawat numero sa set ng datos at ng mean upang gawin silang positibo, pagdadagdag ng lahat ng mga ito upang mahanap ang kanilang suma, at sa wakas ay paghahati ng suma sa pamamagitan ng bilang ng mga halaga sa set ng datos minus 1. Kinukuha natin ang 1 mula sa bilang ng mga halaga upang itama ang bias na natatanggap natin mula sa paggamit ng isang sample sa halip na isang buong populasyon. Ito ay tinatawag na Bessel's correction.
- Standard Deviation: Ang dispersion, o pagkalat, ng dataset na nauugnay sa kanyang mean. Habang binibigyan tayo ng rough idea ng pagkalat ng variance, ang standard deviation ay nagbibigay sa atin ng eksaktong mga distansya sa pagitan ng mga termino sa set at ang mean ng set. Kung ang mga data point ay mas malalayo mula sa mean, mayroong mas mataas na deviation sa loob ng data set; samakatuwid, kung gaano kalawak na kalat ang data, mas mataas ang standard deviation. Ang standard deviation ay katumbas ng square root ng variance.