
Kalkulatori ya Tiger Algebra
Usambazaji wa kawaida na wa kawaida wa kiwango
Usambazaji wa kawaida
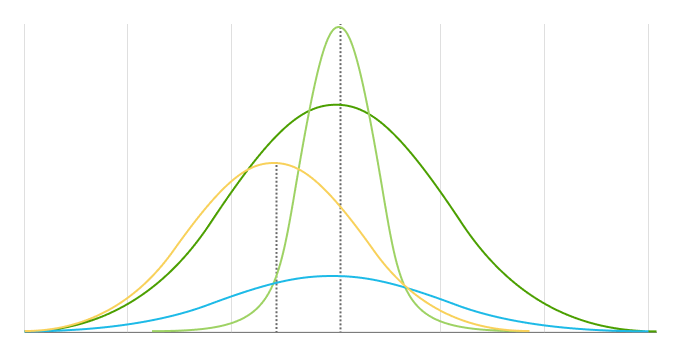
Usambazaji wa kawaida (pia inajulikana kama Gaussian, Gauss, au Laplace–Gauss, au bell curve) ni usambazaji wa uwezekano wa kuunganisha uwezekano wa kufanya kazi na variable ya random . Kitovu cha usambazaji wa kawaida kipo kila wakati kwenye wastani, ambapo usambazaji ni sawa kabisa.
Maandishi
Wastatishi kwa kawaida hutumia herufi kubwa kurepresent variable za random na herufi ndogo kurepresent thamani zao. Kwa mfano:
Mifano mingine
: Ni uwezekano upi kwamba ni kubwa kuliko ?
: Ni uwezekano upi kwamba ni ndogo kuliko ?
: Ni uwezekano upi kwamba iko kati ya na ?
: Ni uwezekano upi kwamba ni kubwa kuliko na ndogo kuliko ?
Vigezo vya usambazaji wa kawaida
Ukubwa wa wastani na deviation vya kiwango ndio vigezo viwili vikuu vya usambazaji wa kawaida. Wanaamua sura ya usambazaji na uwezekano.
Wastani
au
Ukubwa wa wastani ni mahali pako pakati na kilele cha usambazaji, maana yake mabadiliko yoyote kwenye wastani husonga curve ya usambazaji kushoto au kulia kwenye axis ya x. Data nyingi (thamani) zipo karibu na wastani.
Deviation ya kiwango
au
Deviation ya kiwango inapima umbali gani data iko mbali na wastani wa usambazaji. Inaamua upana wa usambazaji wa kawaida. Deviation kubwa za kiwango husababisha curves fupi, pana na deviations ndogo za kiwango husababisha curves kubwa, nyembamba.
Mali za usambazaji wa kawaida
Usambazaji wa kawaida wa kiwango
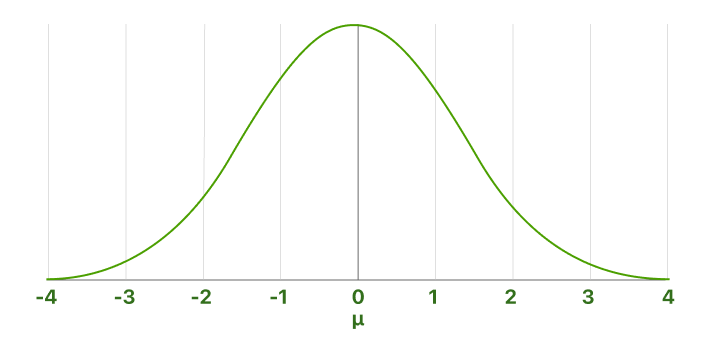
Usambazaji wa kawaida wa kiwango ni kesi maalum ya usambazaji wa kawaida ambapo wastani ni sifuri na deviation ya kiwango ni moja. Usambazaji huu pia unajulikana kama Z-distribution.
Maandishi
Scores za kiwango
Thamani kwenye usambazaji wa kawaida wa kiwango inaitwa score ya kiwango au z-score. Inawakilisha deviations ya kiwango juu au chini ya wastani ambapo uchunguzi fulani unaanguka.
Kwa mfano, score ya kiwango ya inaonyesha kuwa uchunguzi ni deviations ya kiwango juu ya wastani. Negative score ya kiwango inawakilisha thamani chini ya wastani. Wastani una z-score ya .
Zaidi ya 99.9% ya visa vyote vipo ndani ya +/- 3.9 deviations za kiwango kutoka kwa wastani. Kwa hiyo, tunachukulia uwezekano wa data yoyote na z-score kubwa kuliko au ndogo kuliko kama 0%. Kwa maneno mengine, tunachukulia interval kati ya na kama 100% ya usambazaji wa kawaida wa kiwango.
Kupata maeneo chini ya curve ya usambazaji wa kawaida wa kiwango
Usambazaji wa kawaida ni usambazaji wa uwezekano. Kama na usambazaji wowote wa uwezekano, uwiano wa eneo linaloanguka chini ya curve kati ya point mbili kwenye plot ya usambazaji wa uwezekano unaonyesha uwezekano kwamba thamani itaanguka ndani ya interval hiyo.
Eneo chini ya curve ni sawa na , na ni 100% ya usambazaji. =100%.
Unapopata z-score, unaweza kupata eneo hadi kwenye yeye kwa kutazama meza ya usambazaji wa kawaida wa kiwango. Pia inaitwa meza ya z-scores. (link kwenye meza inakuja hivi karibuni)
Kwa sababu meza ya z-scores inaonyesha eneo hadi kwenye thamani ya z-score, unapotaka kupata uwezekano wa data na z-scores kubwa, unahitaji kubomoa nambari kutoka kwenye meza kutoka kwa . Hii inaweza kuonyeshwa kama rule:
Hazipopatikani z-score kamili kwenye meza, tunachagua karibu zaidi. Ikiwa z-scores 2 zilizo karibu zaidi zina umbali sawa kutoka kwa z-score yetu iliyotakiwa, tunahesabu wastani wao.
Mifano mingine
- Ni uwezekano upi wa data na z-score ambayo ni kubwa kuliko ?
- Ni uwezekano upi wa data na z-score ambayo ni ndogo kuliko ?
- Ni uwezekano upi wa data na z-score ambayo ni kati ya na ?
- Ni uwezekano upi wa data na z-score ambayo ni kubwa kuliko na ndogo kuliko ?
Kuweka kwenye kiwango
Kuhesabu z-scores
Scores za kiwango ni njia nzuri ya kuelewa wapi maoni fulani yanaanguka kuhusiana na usambazaji wa kawaida kwa ujumla. Wanakuwezesha kuchukua maoni yaliyopatikana kutoka kwenye idadi ya watu kwa usambazaji wa kawaida na tunu na deviations za kiwango tofauti na kuweka kwenye kiwango. Baada ya kuweka data yako kwenye kiwango, unaweza kuiweka ndani ya usambazaji wa kawaida wa kiwango.
Kwa njia hii, kuweka kwenye kiwango kunakuwezesha kulinganisha aina tofauti za maoni kulingana na kila maoni yanaanguka ndani ya usambazaji wake.
Kuhesabu score ya kiwango kwa maoni, chukua kipimo cha raw, punguza wastani, na gawa na deviation ya kiwango. Kihisabati, fomu ya mchakato huo ni ifuatayo:
inawakilisha thamani unayo ya kipimo cha masilahi. Ni thamani ya kuweka kwenye kiwango - wakati mwingine inaitwa data point.
(Mu) na (sigma) inawakilisha vigezo kwa idadi ya watu ambako maoni yalichukuliwa.
Matemu zaidi yanayohusiana
Skewness
Skewness inarejelea upotoshaji au kutosawa ambayo inatoka kutoka kwenye bell curve symmetrical, au usambazaji wa kawaida, katika set ya data. Ikiwa curve imehamishiwa kushoto au kulia, inasemekana kuwa skewed. Skewness inaweza kufafanuliwa kama uakilishi wa kiwango ambacho usambazaji fulani unatofauti na usambazaji wa kawaida. Skewness inatofautisha thamani za hali ya juu katika mkia mmoja dhidi ya nyingine. Usambazaji wa kawaida una skew ya sifuri.
Kurtosis
Kurtosis inapima thamani za hali ya juu kwenye kila mkia. Usambazaji na kurtosis kubwa unaonyesha data ya mkia inayozidi mikia ya usambazaji wa kawaida. Usambazaji wenye kurtosis ya chini unaonyesha data ya mkia ambayo kwa ujumla ni chini ya hali ya juu kuliko mikia ya usambazaji wa kawaida. Kurtosis ni kipimo cha uzito uliochanganywa wa mikia ya usambazaji kuhusiana na kitovu cha usambazaji. Wakati set ya data ambayo ni karibu na kawaida inapokwa kwenye histogram, huonyesha peak ya bell na data nyingi ndani ya deviations tatu za kiwango (plus au minus) wa wastani. Hata hivyo, wakati kurtosis ya juu ipo, mikia inazidi deviations tatu za kiwango za usambazaji wa bell-curved normal.
Usambazaji wa kawaida (pia inajulikana kama Gaussian, Gauss, au Laplace–Gauss, au bell curve) ni usambazaji wa uwezekano wa kuunganisha uwezekano wa kufanya kazi na variable ya random . Kitovu cha usambazaji wa kawaida kipo kila wakati kwenye wastani, ambapo usambazaji ni sawa kabisa.
Maandishi
Wastatishi kwa kawaida hutumia herufi kubwa kurepresent variable za random na herufi ndogo kurepresent thamani zao. Kwa mfano:
- ndio thamani ya variable ya random .
- inawakilisha uwezekano wa .
- inawakilisha uwezekano kwamba variable ya random ni sawa na thamani maalum . Kwa mfano, inahusisha uwezekano kwamba variable ya random ni sawa na .
Mifano mingine
: Ni uwezekano upi kwamba ni kubwa kuliko ?
: Ni uwezekano upi kwamba ni ndogo kuliko ?
: Ni uwezekano upi kwamba iko kati ya na ?
: Ni uwezekano upi kwamba ni kubwa kuliko na ndogo kuliko ?
Vigezo vya usambazaji wa kawaida
Ukubwa wa wastani na deviation vya kiwango ndio vigezo viwili vikuu vya usambazaji wa kawaida. Wanaamua sura ya usambazaji na uwezekano.
Wastani
au
Ukubwa wa wastani ni mahali pako pakati na kilele cha usambazaji, maana yake mabadiliko yoyote kwenye wastani husonga curve ya usambazaji kushoto au kulia kwenye axis ya x. Data nyingi (thamani) zipo karibu na wastani.
Deviation ya kiwango
au
Deviation ya kiwango inapima umbali gani data iko mbali na wastani wa usambazaji. Inaamua upana wa usambazaji wa kawaida. Deviation kubwa za kiwango husababisha curves fupi, pana na deviations ndogo za kiwango husababisha curves kubwa, nyembamba.
Mali za usambazaji wa kawaida
- ni symmetrical
Usambazaji wa kawaida ni sawa kabisa, maana curve ya usambazaji inaweza kufungwa katikati, kwenye wastani, kuunda nusu mbili zinazofanana. Ushabaha huu ni matokeo ya nusu ya uchunguzi kuanguka kila upande wa curve. - Wastani, median, na mode ni sawa
Kwa sababu usambazaji wa kawaida ni symmetrical, kitovu chake kinarepresent wastani, au wastani, wa data zote. Hii inamaanisha kwamba median (thamani katikati ya seti wakati thamani zake zinaamriwa kutoka mdogo hadi mkubwa) pia iko katikati ya usambazaji na ni sawa na wastani. Kilele, kilele cha juu kabisa cha curve ya usambazaji, pia kwa kawaida iko katikati ya chati, maana mode ya usambazaji, thamani inayojirudia mara kwa mara na, kwa hivyo, sehemu ya juu kabisa kwenye graph, pia iko katikati ya usambazaji. Data hizi za usambazaji wa kawaida zinawakilisha data zinazotokea. Wastani ni kitovu cha usambazaji kwa sababu wastani ndio hatua inayotokea mara kwa mara. Middlepoint pia ni hatua ambapo mizani hii inajikuta. Vipimo kawaida ni sawa katika usambazi kamili (kawaida). Nusu ya idadi ya watu ni chini ya wastani, na nusu ni kubwa kuliko wastani. - Emirical rule
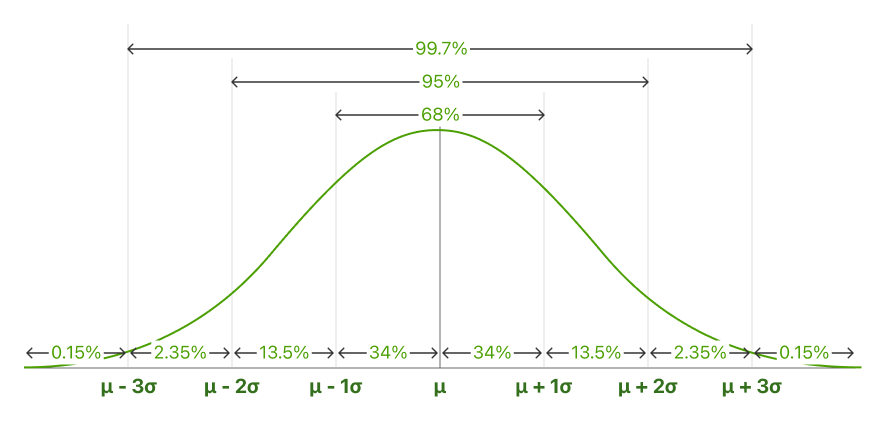
Pia inaitwa 68-95-99.7 rule. Sheria ya emirical inaelezea asilimia ya data zinazoanguka ndani ya biladi za deviation za kiwango kutoka kwa wastani kwa curves inayopiga kengele.
Katika data imesambazwa kwa kawaida, kuna sehemu ya umbali inadumu chini ya curve kati ya wastani na idadi ya biladi za deviation kutoka kwa wastani. Sheria ya Emirical inakuwezesha kubaini uwiano wa thamani zinazoanguka ndani ya umbali wa wastani.
68.25% ya visa vyote viko ndani ya +/- one deviation ya kiwango kutoka kwa wastani.
95% ya visa vyote viko ndani ya +/- two deviations za kiwango kutoka kwa wastani.
99.7% ya visa vyote viko ndani ya +/- three deviations za kiwango kutoka kwa wastani.
Usambazaji wa kawaida wa kiwango
Usambazaji wa kawaida wa kiwango ni kesi maalum ya usambazaji wa kawaida ambapo wastani ni sifuri na deviation ya kiwango ni moja. Usambazaji huu pia unajulikana kama Z-distribution.
Maandishi
- ndio "z-score" (score ya kiwango) - z score ni deviations ngapi za kiwango thamani iko mbali na wastani.
- (mu) ni wastani.
- (sigma") ni deviation ya kiwango.
Scores za kiwango
Thamani kwenye usambazaji wa kawaida wa kiwango inaitwa score ya kiwango au z-score. Inawakilisha deviations ya kiwango juu au chini ya wastani ambapo uchunguzi fulani unaanguka.
Kwa mfano, score ya kiwango ya inaonyesha kuwa uchunguzi ni deviations ya kiwango juu ya wastani. Negative score ya kiwango inawakilisha thamani chini ya wastani. Wastani una z-score ya .
Zaidi ya 99.9% ya visa vyote vipo ndani ya +/- 3.9 deviations za kiwango kutoka kwa wastani. Kwa hiyo, tunachukulia uwezekano wa data yoyote na z-score kubwa kuliko au ndogo kuliko kama 0%. Kwa maneno mengine, tunachukulia interval kati ya na kama 100% ya usambazaji wa kawaida wa kiwango.
Kupata maeneo chini ya curve ya usambazaji wa kawaida wa kiwango
Usambazaji wa kawaida ni usambazaji wa uwezekano. Kama na usambazaji wowote wa uwezekano, uwiano wa eneo linaloanguka chini ya curve kati ya point mbili kwenye plot ya usambazaji wa uwezekano unaonyesha uwezekano kwamba thamani itaanguka ndani ya interval hiyo.
Eneo chini ya curve ni sawa na , na ni 100% ya usambazaji. =100%.
Unapopata z-score, unaweza kupata eneo hadi kwenye yeye kwa kutazama meza ya usambazaji wa kawaida wa kiwango. Pia inaitwa meza ya z-scores. (link kwenye meza inakuja hivi karibuni)
Kwa sababu meza ya z-scores inaonyesha eneo hadi kwenye thamani ya z-score, unapotaka kupata uwezekano wa data na z-scores kubwa, unahitaji kubomoa nambari kutoka kwenye meza kutoka kwa . Hii inaweza kuonyeshwa kama rule:
Hazipopatikani z-score kamili kwenye meza, tunachagua karibu zaidi. Ikiwa z-scores 2 zilizo karibu zaidi zina umbali sawa kutoka kwa z-score yetu iliyotakiwa, tunahesabu wastani wao.
Mifano mingine
- Ni uwezekano upi wa data na z-score ambayo ni kubwa kuliko ?
- Ni uwezekano upi wa data na z-score ambayo ni ndogo kuliko ?
- Ni uwezekano upi wa data na z-score ambayo ni kati ya na ?
- Ni uwezekano upi wa data na z-score ambayo ni kubwa kuliko na ndogo kuliko ?
Kuweka kwenye kiwango
Kuhesabu z-scores
Scores za kiwango ni njia nzuri ya kuelewa wapi maoni fulani yanaanguka kuhusiana na usambazaji wa kawaida kwa ujumla. Wanakuwezesha kuchukua maoni yaliyopatikana kutoka kwenye idadi ya watu kwa usambazaji wa kawaida na tunu na deviations za kiwango tofauti na kuweka kwenye kiwango. Baada ya kuweka data yako kwenye kiwango, unaweza kuiweka ndani ya usambazaji wa kawaida wa kiwango.
Kwa njia hii, kuweka kwenye kiwango kunakuwezesha kulinganisha aina tofauti za maoni kulingana na kila maoni yanaanguka ndani ya usambazaji wake.
Kuhesabu score ya kiwango kwa maoni, chukua kipimo cha raw, punguza wastani, na gawa na deviation ya kiwango. Kihisabati, fomu ya mchakato huo ni ifuatayo:
inawakilisha thamani unayo ya kipimo cha masilahi. Ni thamani ya kuweka kwenye kiwango - wakati mwingine inaitwa data point.
(Mu) na (sigma) inawakilisha vigezo kwa idadi ya watu ambako maoni yalichukuliwa.
Matemu zaidi yanayohusiana
Skewness
Skewness inarejelea upotoshaji au kutosawa ambayo inatoka kutoka kwenye bell curve symmetrical, au usambazaji wa kawaida, katika set ya data. Ikiwa curve imehamishiwa kushoto au kulia, inasemekana kuwa skewed. Skewness inaweza kufafanuliwa kama uakilishi wa kiwango ambacho usambazaji fulani unatofauti na usambazaji wa kawaida. Skewness inatofautisha thamani za hali ya juu katika mkia mmoja dhidi ya nyingine. Usambazaji wa kawaida una skew ya sifuri.
Kurtosis
Kurtosis inapima thamani za hali ya juu kwenye kila mkia. Usambazaji na kurtosis kubwa unaonyesha data ya mkia inayozidi mikia ya usambazaji wa kawaida. Usambazaji wenye kurtosis ya chini unaonyesha data ya mkia ambayo kwa ujumla ni chini ya hali ya juu kuliko mikia ya usambazaji wa kawaida. Kurtosis ni kipimo cha uzito uliochanganywa wa mikia ya usambazaji kuhusiana na kitovu cha usambazaji. Wakati set ya data ambayo ni karibu na kawaida inapokwa kwenye histogram, huonyesha peak ya bell na data nyingi ndani ya deviations tatu za kiwango (plus au minus) wa wastani. Hata hivyo, wakati kurtosis ya juu ipo, mikia inazidi deviations tatu za kiwango za usambazaji wa bell-curved normal.