
타이거 알지브라 계산기
통계 계수
개요:
통계학의 적용 범위는 데이터의 수집, 분석, 해석, 재성당성 확인에 이릅니다. 통계학은 주로 모집단과 관련하여 다루는데, 모집단은 이해하기 쉽게 해다는 사람들, 사물, 또는 객체들의 집합을 의미합니다. 어떤 모집단에 대한 정보를 얻기 위해, 우리는 그 모집단을 대표하는 작은 표본, 즉 부분 집합을 선택할 수 있습니다. 선택된 이 표본이 모집단을 얼마나 잘 대표하느냐에 따라 데이터의 정확성이 결정됩니다.예를 들어, 학교 전체의 평균학점을 계산하고자 할 때, 우리는 전체 학생을 대상으로하지 않고 각 등급 및 클래스에서 몇몇 학생들을 선택할 수 있습니다. 이러한 선택된 표본에서 수집한 데이터는 학생들의 평균학점이 될 것이며, 모집단은 학교의 모든 학생, 표본은 선택된 학생이 될 것입니다.
표본분산 공식:
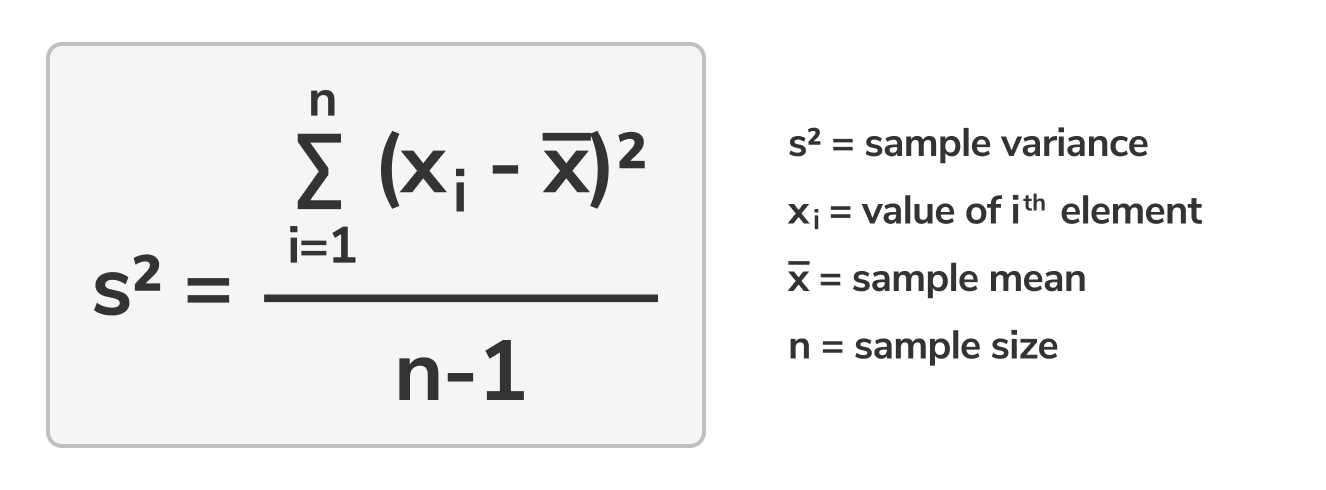
관련 개념:
- 평균: 집합에 있는 모든 숫자의 평균 . 평균을 구하기 위해서는 모든 숫자의 합을 세트의 항목 수로 나눕니다. 평균은 때때로 등차 평균이라고도 불립니다.
- 중앙값: 정렬된 숫자 목록의 가운데 항목. 집합에 짝수 개의 항목이 있으면 중앙값은 두 가운데 항목의 평균과 같습니다.
- 범위: 집합에서 최소값과 최대값의 차이. 집합의 가장 큰 숫자에서 가장 작은 숫자를 빼서 계산합니다.
- 분산: 한 세트 안의 각 숫자가 평균과 그리고 그러므로 세트 안의 다른 모든 숫자로부터 얼마나 멀리 떨어져 있는지. 분산이 클수록 세트의 숫자들은 평균과 그리고 서로로부터 멀어집니다. 표본의 분산은 종종 기호로 표시되며, 모집단의 분산은 종종 기호로 표시됩니다. 통계에서는 표본의 분산을 구하는 것이 더욱 일반적입니다. 분산은 데이터 세트와 평균 사이의 차이를 제곱하여 그것들을 양수로 만들고, 그들의 합을 찾아내서 그 합을 데이터 세트의 값 수에서 1을 뺀 수로 나눔으로써 계산됩니다. 표본 대신 전체 모집단을 사용하였기 때문에 우리가 얻는 편향을 수정하기 위해 값의 수에서 1을 뺍니다. 이것을 Bessel의 수정이라고 합니다.
- 표준 편차: 평균에 대한 데이터 집합의 분산, 또는 흩어져 있는 정도. 분산은 분포도에 대한 대략적인 아이디어를 제공하는 반면, 표준편차는 세트의 항목들과 세트의 평균 사이의 정확한 거리를 제공합니다. 데이터 포인트가 평균에서 더 멀리 떨어져 있다면, 데이터 세트 내에서 더 큰 편차가 있게 됩니다; 고로, 데이터가 더 퍼져 있으면 표준 편차가 더 크게 됩니다. 표준 편차는 분산의 제곱근과 같습니다.