
टाइगर बीजगणित कैलकुलेटर
सांख्यिकीय मापदंड
सामान्य:
सांख्यिकीय विज्ञान आंकड़ों के संग्रहण, विश्लेषण, व्याख्या, और प्रस्तुति के साथ संबंधित होता है। सांख्यिकी अक्सर जनसंख्याओं के साथ संबंधित होती है, जिसे सबसे अच्छे रूप में व्यक्तियों, चीजों, या वस्तुओं के समूह के रूप में सोचा जा सकता है। एक जनसंख्या के बारे में जानकारी प्राप्त करने के लिए, हम एक छोटा नमूना चुन सकते हैं, जिसे अक्सर एक सबसेट के रूप में संदर्भित किया जाता है, जो एक जनसंख्या का प्रतिनिधि होता है। नमूना जितना जनसंख्या का प्रतिनिधित्व करता है, आंकड़े उतने ही सटीक होते हैं।उदाहरण के लिए, अगर आप अपने स्कूल में कुल ग्रेड पॉइंट औसत की गणना कर रहे थे, तो आप पूरे छात्र निकाय के बजाय प्रत्येक ग्रेड या क्लास से कुछ छात्रों का चयन कर सकते थे। नमूना से एकत्रित डाटा छात्रों के ग्रेड पॉइंट औसत होंगे, जनसंख्या आपके स्कूल के सभी छात्र होंगे, और नमूना चयनित छात्र होंगे।
नमूना विभेदन सूत्र:
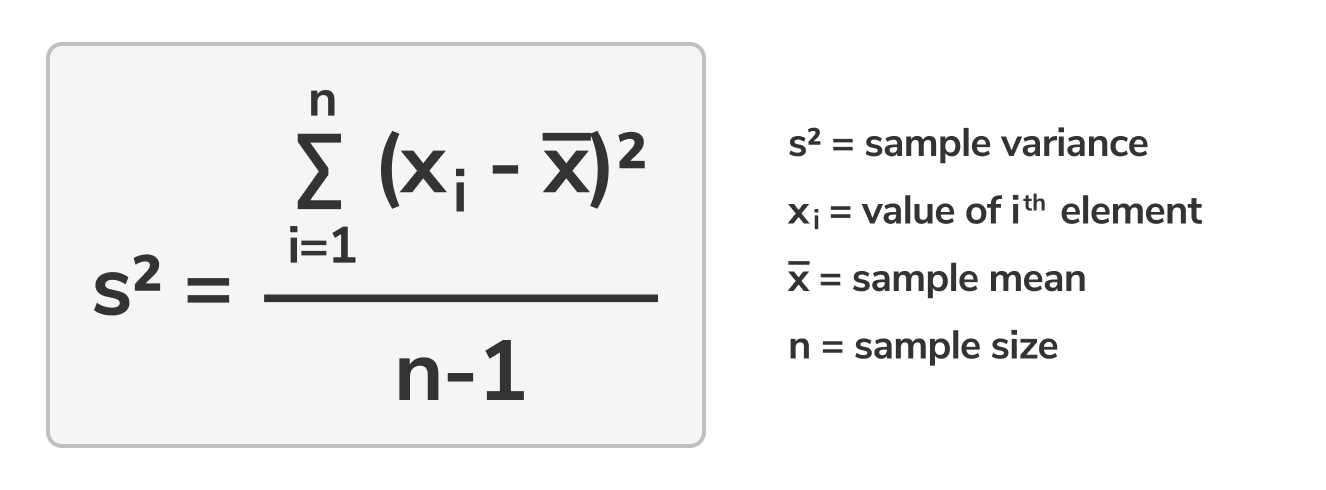
संबंधित अवधारणाएं:
- Mean: सेट की सभी संख्याओं का औसत। मीन निकालने के लिए, सभी संख्याओं को जोड़कर संख्याओं की संख्या द्वारा परिणाम को विभाजित करें। अवगाही कभी-कभी गणितीय माध्य भी कहलाती है।
- Median: सूचीभूत संख्याओं की मध्य संख्या। संख्या के सेट में समान संख्या के साथ, मध्यमांक दो केंद्रीय शर्तों के माध्य से बराबर होता है।
- Range: सेट में सबसे छोटे और बड़े मूल्यों के बीच का अंतर। सेट में सबसे छोटा नम्बर सबसे बड़े नंबर से घटाएं।
- Variance: सेट में प्रत्येक संख्या मीन से कितनी दूर है और फिर, सेट में हर अन्य संख्या से। विभेद बड़ा होता है, संख्याएं सेट में मीन और एक-दूसरे से दूर होती हैं। के प्रतीक द्वारा एक नमूने की विभेदन का प्रतिनिधित्व किया जाता है जबकि एक जनसंख्या की विभेद का प्रतिनिधित्व अक्सर प्रतीक द्वारा किया जाता है। सांख्यिकी में, यह आमतौर पर एक नमूने के लिए विभेदन पा है।
- Standard Deviation: एक डेटासेट के माध्य से फैलाव, या फैलाव। जबकि विभेद हमें फैलाव का अनुमान देता है, मानक विचलन हमें सेट में औसत के बीच और शर्तों के बीच सटीक दूरियां देता है। अगर डेटा बिंदु औसत से दूर है, तो डेटा सेट में अधिक विचलन होता है; इस प्रकार, डेटा जितना अधिक फैला हुआ है, मानक विचलन उतना अधिक होता है। मानक विचलन विभेद के वर्गमूल के बराबर होता है।