
Calculatrice Tiger Algebra
Distributions normale et standard normale
Distribution normale
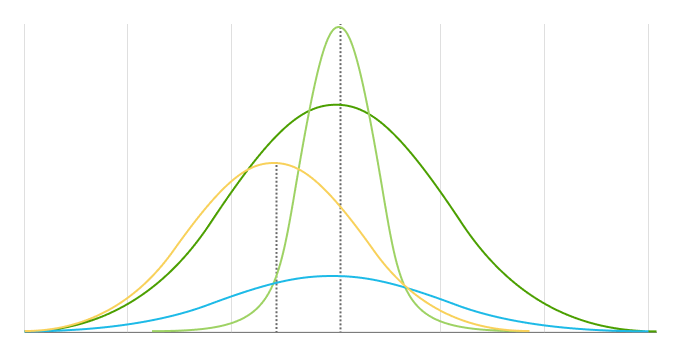
Une distribution normale (également connue sous le nom de distribution de Gauss, Gauss, ou Laplace–Gauss, ou la courbe de bell) est une distribution de probabilité qui relète une probabilité cumulée avec une variable aléatoire . Le centre d'une distribution normale est toujours situé à la moyenne, à travers lequel la distribution est complètement symétrique.
Notations
Les statisticiens utilisent généralement des lettres majuscules pour représenter les variables aléatoires et des lettres minuscules pour représenter leurs valeurs. Par exemple:
Autres exemples
: Quelle est la probabilité que soit plus grand que ?
: Quelle est la probabilité que soit inférieur à ?
: Quelle est la probabilité que soit entre et ?
: Quelle est la probabilité que soit plus grand que et moins que ?
Paramètres de la distribution normale
La moyenne et l'écart type sont les deux principaux paramètres d'une distribution normale. Ils déterminent à la fois la forme de la distribution et les probabilités.
Moyenne
ou
La moyenne est la localisation du centre et du pic d'une distribution, ce qui signifie que tout changement de la moyenne déplace la courbe de la distribution à gauche ou à droite le long de l'axe des x. La plupart des points de données (valeurs) sont situés autour de la moyenne.
Écart type
ou
L'écart type mesure à quelle distance les points de données sont de la moyenne d'une distribution. Il détermine la largeur d'une distribution normale. Un écart type plus grand donne des courbes plus courtes et plus larges, et des écarts types plus petits donnent des courbes plus hautes et plus étroites.
Propriétés de la distribution normale
Distribution normale standard
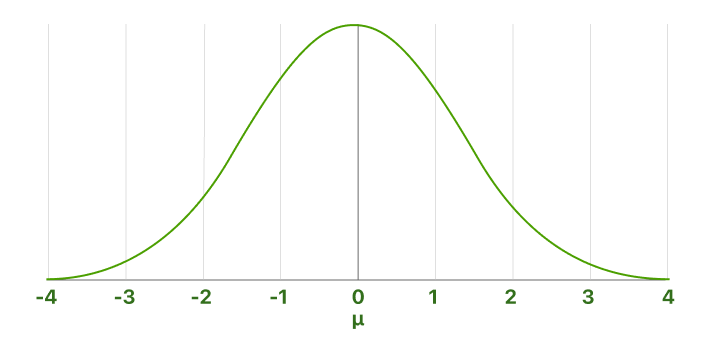
La distribution normale standard est un cas particulier de la distribution normale où la moyenne est zéro et l'écart type est un. Cette distribution est aussi appelée la distribution Z.
Notations
Scores standards
Une valeur sur la distribution normale standard est appelée un score standard ou un z-score. Il représente le nombre d'écarts types au-dessus ou en dessous de la moyenne qu'une observation spécifique tombe.
Par exemple, un score standard de indique que l'observation est écart types au-dessus de la moyenne. Un score standard négatif représente une valeur inférieure à la moyenne. La moyenne a un z-score de .
Plus de 99,9% de tous les cas tombent à +/- 3,9 écarts types de la moyenne. Nous considérons donc la probabilité de toutes les données avec un score z supérieur à ou inférieur à comme étant de 0%. En d'autres termes, nous considérons l'intervalle entre et comme 100% de la distribution normale standard.
Trouver des zones sous la courbe d'une distribution normale standard
La distribution normale est une distribution de probabilité. Comme pour toute distribution de probabilité, la proportion de la surface qui tombe sous la courbe entre deux points sur un graphique de distribution de probabilité indique la probabilité qu'une valeur tombe dans cet intervalle.
La surface sous la courbe égale , et c'est 100% de la distribution. =100%.
Lorsque vous obtenez un score z, vous pouvez trouver la zone jusqu'à lui en regardant un tableau de distribution normale standard. Aussi connu sous le nom de tableau des scores z. (le lien vers le tableau arrive bientôt)
Parce que le tableau des scores z montre la zone jusqu'à la valeur du score z, lorsque vous voulez trouver la probabilité de données avec des scores z plus grands, vous devez soustraire le nombre du tableau de . Ceci peut être montré comme une règle:
Quand nous ne trouvons pas le score z parfait dans le tableau, nous choisissons le plus proche. Si les 2 scores z les plus proches sont à la même distance de notre score z voulu, nous calculons leur moyenne.
Autres exemples
- Quelle est la probabilité de données avec un score z qui est plus grand que ?
- Quelle est la probabilité de données avec un score z qui est plus petit que ?
- Quelle est la probabilité de données avec un score z qui est entre et ?
- Quelle est la probabilité de données avec un score z qui est plus grand que et plus petit que ?
Standardisation
Calcul des scores z
Les scores standards sont un excellent moyen de comprendre où une observation spécifique tombe par rapport à l'ensemble de la distribution normale. Ils permettent également de prendre des observations tirées de populations normalement distribuées avec des moyennes et des écarts types différents et de les placer sur une échelle standard. Après avoir standardisé vos données, vous pouvez les placer dans la distribution normale standard.
De cette manière, la standardisation vous permet de comparer différents types d'observations en fonction de l'endroit où chaque observation tombe dans sa propre distribution.
Pour calculer le score standard d'une observation, prenez la mesure brute, soustrayez la moyenne et divisez par l'écart type. Mathématiquement, la formule pour ce processus est la suivante:
représente la valeur brute de la mesure d'intérêt. C'est la valeur à standardiser - parfois appelée le point de données.
(mu) et (sigma) représentent les paramètres pour la population dont l'observation a été tirée.
Plus de termes liés
Asymétrie
L'asymétrie se réfère à une distorsion ou une asymétrie qui s'écarte de la courbe de cloche symétrique, ou distribution normale, dans un ensemble de données. Si la courbe est décalée vers la gauche ou la droite, on dit qu'elle est asymétrique. L'asymétrie peut être quantifiée comme une représentation de l'étendue à laquelle une distribution donnée varie d'une distribution normale. L'asymétrie différencie les valeurs extrêmes dans une queue versus l'autre. Une distribution normale a une asymétrie de zéro.
Kurtosis
La kurtosis mesure les valeurs extrêmes dans chaque queue. Les distributions ayant une grande kurtose présentent des données de queue dépassant les queues de la distribution normale. Les distributions ayant une faible kurtose présentent généralement des données de queue qui sont moins extrêmes que les queues de la distribution normale. La kurtose est une mesure du poids combiné des queues d'une distribution par rapport au centre de la distribution. Lorsqu'un ensemble de données approximativement normales est représenté par un histogramme, il montre un pic de bell et la plupart des données à trois écarts-types (plus ou moins) de la moyenne. Cependant, lorsque la kurtosis est élevée, les queues s'étendent plus loin que les trois écarts types de la distribution normale en forme de cloche.
Une distribution normale (également connue sous le nom de distribution de Gauss, Gauss, ou Laplace–Gauss, ou la courbe de bell) est une distribution de probabilité qui relète une probabilité cumulée avec une variable aléatoire . Le centre d'une distribution normale est toujours situé à la moyenne, à travers lequel la distribution est complètement symétrique.
Notations
Les statisticiens utilisent généralement des lettres majuscules pour représenter les variables aléatoires et des lettres minuscules pour représenter leurs valeurs. Par exemple:
- est la valeur de la variable aléatoire .
- représente la probabilité de .
- représente la probabilité que la variable aléatoire soit égale à une valeur particulière . Par exemple, fait référence à la probabilité que la variable aléatoire soit égale à .
Autres exemples
: Quelle est la probabilité que soit plus grand que ?
: Quelle est la probabilité que soit inférieur à ?
: Quelle est la probabilité que soit entre et ?
: Quelle est la probabilité que soit plus grand que et moins que ?
Paramètres de la distribution normale
La moyenne et l'écart type sont les deux principaux paramètres d'une distribution normale. Ils déterminent à la fois la forme de la distribution et les probabilités.
Moyenne
ou
La moyenne est la localisation du centre et du pic d'une distribution, ce qui signifie que tout changement de la moyenne déplace la courbe de la distribution à gauche ou à droite le long de l'axe des x. La plupart des points de données (valeurs) sont situés autour de la moyenne.
Écart type
ou
L'écart type mesure à quelle distance les points de données sont de la moyenne d'une distribution. Il détermine la largeur d'une distribution normale. Un écart type plus grand donne des courbes plus courtes et plus larges, et des écarts types plus petits donnent des courbes plus hautes et plus étroites.
Propriétés de la distribution normale
- Elle est symétrique
La distribution normale est parfaitement symétrique, ce qui signifie que la courbe de distribution peut être pliée au milieu, le long de la moyenne, pour produire deux moitiés identiques. Cette forme symétrique résulte du fait qu'une moitié des observations tombe de chaque côté de la courbe. - La moyenne, la médiane et le mode sont tous égaux
Parce que la distribution normale est symétrique, son centre représente la moyenne, ou la moyenne, de tous les points de données. Cela signifie que sa médiane (la valeur au milieu d'un ensemble lorsque ses valeurs sont ordonnées du moins grand au plus grand) est également située au centre de la distribution et est identique à la moyenne. Le sommet, le point le plus haut de la courbe de distribution normale, se trouve également au centre du graphe, ce qui signifie que le mode de la distribution, sa valeur la plus couramment observée et, par conséquent, le point le plus haut sur le graphe, est également situé au centre de la distribution. Ces données de la distribution normale représentent les points de données (valeurs) qui se produisent. La moyenne est le centre de la distribution parce que la moyenne est le point qui se produit le plus fréquemment. Le point médian est également le point où tombent ces trois mesures. Les mesures sont généralement égales dans une distribution parfaitement (normale). La moitié de la population est inférieure à la moyenne, et l'autre moitié est supérieure à la moyenne. - La règle empirique
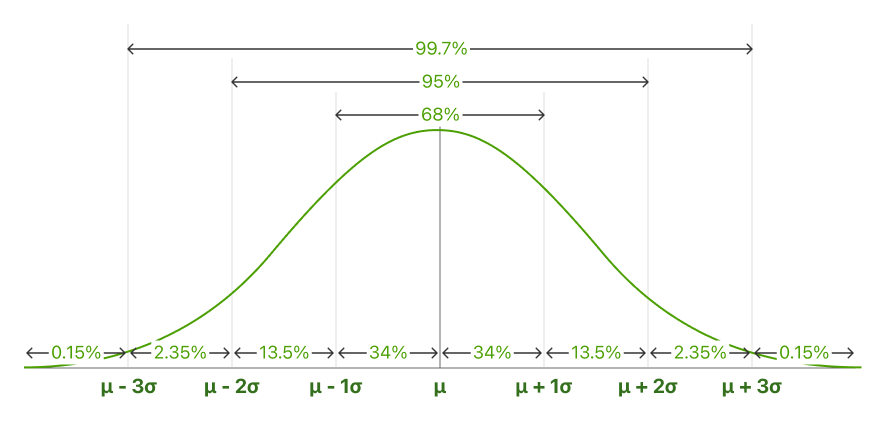
Aussi appelée la règle 68-95-99.7. La règle empirique décrit le pourcentage des données qui tombent dans des nombres spécifiques d'écarts types de la moyenne pour les courbes en forme de cloche.
Dans des données normalement distribuées, il y a une proportion constante de distance sous la courbe entre la moyenne et un nombre spécifique d'écarts types à partir de la moyenne. La règle empirique vous permet de déterminer la proportion de valeurs qui tombent à certaines distances de la moyenne.
68,25% de tous les cas tombent à +/- un écart type de la moyenne.
95% de tous les cas tombent à +/- deux écarts types de la moyenne.
99,7% de tous les cas tombent à +/- trois écarts types de la moyenne.
Distribution normale standard
La distribution normale standard est un cas particulier de la distribution normale où la moyenne est zéro et l'écart type est un. Cette distribution est aussi appelée la distribution Z.
Notations
- est le "score z" (score standard) - le score z est le nombre d'écarts types qu'une valeur est à l'écart de la moyenne.
- (mu) est la moyenne.
- (sigma") est l'écart type.
Scores standards
Une valeur sur la distribution normale standard est appelée un score standard ou un z-score. Il représente le nombre d'écarts types au-dessus ou en dessous de la moyenne qu'une observation spécifique tombe.
Par exemple, un score standard de indique que l'observation est écart types au-dessus de la moyenne. Un score standard négatif représente une valeur inférieure à la moyenne. La moyenne a un z-score de .
Plus de 99,9% de tous les cas tombent à +/- 3,9 écarts types de la moyenne. Nous considérons donc la probabilité de toutes les données avec un score z supérieur à ou inférieur à comme étant de 0%. En d'autres termes, nous considérons l'intervalle entre et comme 100% de la distribution normale standard.
Trouver des zones sous la courbe d'une distribution normale standard
La distribution normale est une distribution de probabilité. Comme pour toute distribution de probabilité, la proportion de la surface qui tombe sous la courbe entre deux points sur un graphique de distribution de probabilité indique la probabilité qu'une valeur tombe dans cet intervalle.
La surface sous la courbe égale , et c'est 100% de la distribution. =100%.
Lorsque vous obtenez un score z, vous pouvez trouver la zone jusqu'à lui en regardant un tableau de distribution normale standard. Aussi connu sous le nom de tableau des scores z. (le lien vers le tableau arrive bientôt)
Parce que le tableau des scores z montre la zone jusqu'à la valeur du score z, lorsque vous voulez trouver la probabilité de données avec des scores z plus grands, vous devez soustraire le nombre du tableau de . Ceci peut être montré comme une règle:
Quand nous ne trouvons pas le score z parfait dans le tableau, nous choisissons le plus proche. Si les 2 scores z les plus proches sont à la même distance de notre score z voulu, nous calculons leur moyenne.
Autres exemples
- Quelle est la probabilité de données avec un score z qui est plus grand que ?
- Quelle est la probabilité de données avec un score z qui est plus petit que ?
- Quelle est la probabilité de données avec un score z qui est entre et ?
- Quelle est la probabilité de données avec un score z qui est plus grand que et plus petit que ?
Standardisation
Calcul des scores z
Les scores standards sont un excellent moyen de comprendre où une observation spécifique tombe par rapport à l'ensemble de la distribution normale. Ils permettent également de prendre des observations tirées de populations normalement distribuées avec des moyennes et des écarts types différents et de les placer sur une échelle standard. Après avoir standardisé vos données, vous pouvez les placer dans la distribution normale standard.
De cette manière, la standardisation vous permet de comparer différents types d'observations en fonction de l'endroit où chaque observation tombe dans sa propre distribution.
Pour calculer le score standard d'une observation, prenez la mesure brute, soustrayez la moyenne et divisez par l'écart type. Mathématiquement, la formule pour ce processus est la suivante:
représente la valeur brute de la mesure d'intérêt. C'est la valeur à standardiser - parfois appelée le point de données.
(mu) et (sigma) représentent les paramètres pour la population dont l'observation a été tirée.
Plus de termes liés
Asymétrie
L'asymétrie se réfère à une distorsion ou une asymétrie qui s'écarte de la courbe de cloche symétrique, ou distribution normale, dans un ensemble de données. Si la courbe est décalée vers la gauche ou la droite, on dit qu'elle est asymétrique. L'asymétrie peut être quantifiée comme une représentation de l'étendue à laquelle une distribution donnée varie d'une distribution normale. L'asymétrie différencie les valeurs extrêmes dans une queue versus l'autre. Une distribution normale a une asymétrie de zéro.
Kurtosis
La kurtosis mesure les valeurs extrêmes dans chaque queue. Les distributions ayant une grande kurtose présentent des données de queue dépassant les queues de la distribution normale. Les distributions ayant une faible kurtose présentent généralement des données de queue qui sont moins extrêmes que les queues de la distribution normale. La kurtose est une mesure du poids combiné des queues d'une distribution par rapport au centre de la distribution. Lorsqu'un ensemble de données approximativement normales est représenté par un histogramme, il montre un pic de bell et la plupart des données à trois écarts-types (plus ou moins) de la moyenne. Cependant, lorsque la kurtosis est élevée, les queues s'étendent plus loin que les trois écarts types de la distribution normale en forme de cloche.