
Tiger Algebra-Rechner
Normal- und Standardnormalverteilungen
Normalverteilung
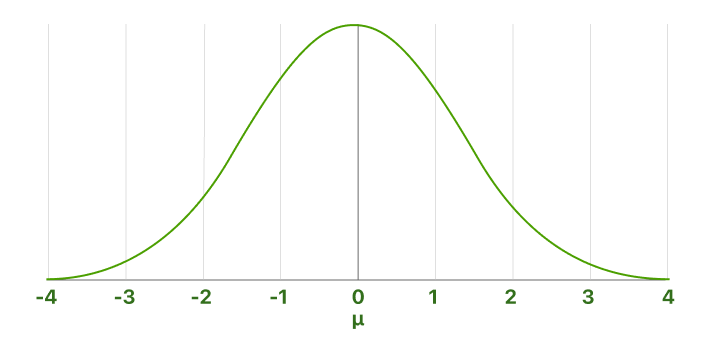
Eine Normalverteilung (auch bekannt als Gaußsche, Gauss, Laplace-Gauss-Verteilung oder Glockenkurve) ist eine Wahrscheinlichkeitsverteilung, die eine kumulative Wahrscheinlichkeit mit einer Zufallsvariablen in Verbindung bringt. Das Zentrum einer Normalverteilung ist immer auf dem Mittelwert gelegen, über den die Verteilung vollkommen symmetrisch ist.
Notationen
Statistiker verwenden normalerweise Großbuchstaben, um Zufallsvariablen darzustellen, und Kleinbuchstaben, um ihre Werte darzustellen. Zum Beispiel:
Weitere Beispiele
: Wie groß ist die Wahrscheinlichkeit, dass größer als ist?
: Wie groß ist die Wahrscheinlichkeit, dass kleiner als ist?
: Wie groß ist die Wahrscheinlichkeit, dass zwischen und liegt?
: Wie groß ist die Wahrscheinlichkeit, dass größer als und kleiner als ist?
Parameter der Normalverteilung
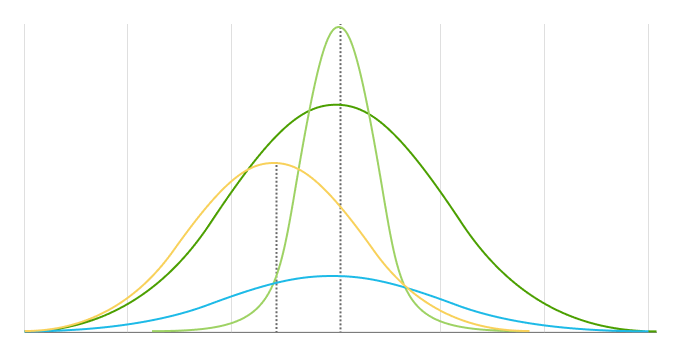
Der Mittelwert und die Standardabweichung sind die zwei Hauptparameter einer Normalverteilung. Sie bestimmen sowohl die Form der Verteilung als auch die Wahrscheinlichkeiten.
Mittelwert
oder
Der Mittelwert ist die Position des Zentrums und des Maximums einer Verteilung. Jede Änderung des Mittelwerts bewegt die Verteilungskurve nach links oder rechts entlang der x-Achse. Die meisten Datenpunkte (Werte) sind um den Mittelwert herum lokalisiert.
Standardabweichung
oder
Die Standardabweichung misst, wie weit Datenpunkte vom Mittelwert einer Verteilung entfernt sind. Sie bestimmt die Breite einer Normalverteilung. Eine größere Standardabweichung resultiert in kürzeren, breiteren Kurven und kleinere Standardabweichungen resultieren in höheren, schmaleren Kurven.
Eigenschaften der Normalverteilung
Standard-Normalverteilung
Die Standard-Normalverteilung ist ein Spezialfall der Normalverteilung, bei dem der Mittelwert null und die Standardabweichung eins ist. Diese Verteilung wird auch als Z-Verteilung bezeichnet.
Notationen
Standardwerte
Ein Wert auf der Standard-Normalverteilung wird als Standardwert oder z-Wert bezeichnet. Er stellt die Anzahl der Standardabweichungen oberhalb oder unterhalb des Mittelwerts dar, in die eine bestimmte Beobachtung fällt.
Zum Beispiel zeigt ein Standardwert von an, dass die Beobachtung Standardabweichungen oberhalb des Mittelwerts liegt. Ein negativer Standardwert repräsentiert einen Wert unter dem Durchschnitt. Der Mittelwert hat einen z-Wert von .
Mehr als 99,9% aller Fälle fallen innerhalb von +/- 3,9 Standardabweichungen vom Mittelwert. Daher betrachten wir die Wahrscheinlichkeit aller Daten mit einem z-Wert, der größer als oder kleiner als ist, als 0%. Mit anderen Worten betrachten wir das Intervall zwischen und als 100% der Standard-Normalverteilung.
Bereiche unter der Kurve einer Standard-Normalverteilung finden
Die Normalverteilung ist eine Wahrscheinlichkeitsverteilung. Wie bei jeder Wahrscheinlichkeitsverteilung gibt der Anteil der Fläche, der unter der Kurve zwischen zwei Punkten auf einem Wahrscheinlichkeitsverteilungsdiagramm liegt, die Wahrscheinlichkeit an, dass ein Wert innerhalb dieses Intervalls fällt.
Die Fläche unter der Kurve beträgt , das entspricht 100% der Verteilung. =100%.
Wenn Sie einen z-Wert haben, können Sie den Bereich bis zu diesem Wert finden, indem Sie in einer Tabelle der Standard-Normalverteilung nachsehen. Auch bekannt als die z-Werte Tabelle. (Der Link zur Tabelle folgt in Kürze)
Da die Z-Werte-Tabelle den Bereich bis zum z-Wert anzeigt, wenn Sie die Wahrscheinlichkeit von Daten mit größeren z-Werten finden möchten, müssen Sie die Zahl aus der Tabelle von abziehen. Dies kann als Regel dargestellt werden:
Wenn wir den perfekten z-Wert in der Tabelle nicht finden, wählen wir den nächstgelegenen. Wenn die beiden nächsten z-Werte den gleichen Abstand zu unserem gewünschten z-Wert haben, berechnen wir ihren Durchschnitt.
Weitere Beispiele
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der größer als ist?
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der kleiner als ist?
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der zwischen und liegt?
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der größer als und kleiner als ist?
Standardisierung
Berechnung der z-Werte
Standardwerte sind ein hervorragendes Mittel, um zu verstehen, wo eine bestimmte Beobachtung im Verhältnis zur gesamten Normalverteilung liegt. Sie ermöglichen es Ihnen auch, Beobachtungen aus normalverteilten Populationen mit unterschiedlichen Mittelwerten und Standardabweichungen zu sammeln und sie auf eine Standard-Skala zu setzen. Nach der Standardisierung Ihrer Daten können Sie sie innerhalb der Standard-Normalverteilung platzieren.
Auf diese Weise ermöglicht die Standardisierung den Vergleich verschiedener Beobachtungen, basierend darauf, wo jede Beobachtung innerhalb ihrer eigenen Verteilung liegt.
Um den Standardwert für eine Beobachtung zu berechnen, nehmen Sie die rohe Messung, subtrahieren den Mittelwert und teilen durch die Standardabweichung. Mathematisch lautet die Formel für diesen Prozess wie folgt:
stellt den Rohwert der interessierenden Messung dar. Es handelt sich dabei um den zu standardisierenden Wert - manchmal auch Datenpunkt genannt.
(Mu) und (Sigma) repräsentieren die Parameter der Population, aus der die Beobachtung stammt.
Weitere verwandte Begriffe
Schiefe
Die Schiefe bezieht sich auf eine Verzerrung oder Asymmetrie, die von der symmetrischen Glockenkurve, oder Normalverteilung, in einer Datenmenge abweicht. Wenn die Kurve nach links oder rechts verschoben ist, spricht man von einer Schiefe. Die Schiefe kann quantifiziert werden als Darstellung des Ausmaßes, in dem eine gegebene Verteilung von einer Normalverteilung abweicht. Die Schiefe unterscheidet extreme Werte in einem gegenüber dem anderen Schwanz. Eine Normalverteilung hat eine Schiefe von null.
Kurtosis
Die Kurtosis misst extreme Werte in beiden Schwänzen. Verteilungen mit großer Kurtosis weisen Enddaten auf, die die Enden der Normalverteilung übertreffen. Verteilungen mit geringer Kurtosis weisen Enddaten auf, die im Allgemeinen weniger extrem sind als die Enden der Normalverteilung. Die Kurtosis ist ein Maß für das kombinierte Gewicht der Schwänze einer Verteilung im Verhältnis zum Zentrum der Verteilung.
Eine Normalverteilung (auch bekannt als Gaußsche, Gauss, Laplace-Gauss-Verteilung oder Glockenkurve) ist eine Wahrscheinlichkeitsverteilung, die eine kumulative Wahrscheinlichkeit mit einer Zufallsvariablen in Verbindung bringt. Das Zentrum einer Normalverteilung ist immer auf dem Mittelwert gelegen, über den die Verteilung vollkommen symmetrisch ist.
Notationen
Statistiker verwenden normalerweise Großbuchstaben, um Zufallsvariablen darzustellen, und Kleinbuchstaben, um ihre Werte darzustellen. Zum Beispiel:
- ist der Wert der Zufallsvariable .
- stellt die Wahrscheinlichkeit von dar.
- stellt die Wahrscheinlichkeit dar, dass die Zufallsvariable gleich einem bestimmten Wert ist. Zum Beispiel bezieht sich auf die Wahrscheinlichkeit, dass die Zufallsvariable gleich ist.
Weitere Beispiele
: Wie groß ist die Wahrscheinlichkeit, dass größer als ist?
: Wie groß ist die Wahrscheinlichkeit, dass kleiner als ist?
: Wie groß ist die Wahrscheinlichkeit, dass zwischen und liegt?
: Wie groß ist die Wahrscheinlichkeit, dass größer als und kleiner als ist?
Parameter der Normalverteilung
Der Mittelwert und die Standardabweichung sind die zwei Hauptparameter einer Normalverteilung. Sie bestimmen sowohl die Form der Verteilung als auch die Wahrscheinlichkeiten.
Mittelwert
oder
Der Mittelwert ist die Position des Zentrums und des Maximums einer Verteilung. Jede Änderung des Mittelwerts bewegt die Verteilungskurve nach links oder rechts entlang der x-Achse. Die meisten Datenpunkte (Werte) sind um den Mittelwert herum lokalisiert.
Standardabweichung
oder
Die Standardabweichung misst, wie weit Datenpunkte vom Mittelwert einer Verteilung entfernt sind. Sie bestimmt die Breite einer Normalverteilung. Eine größere Standardabweichung resultiert in kürzeren, breiteren Kurven und kleinere Standardabweichungen resultieren in höheren, schmaleren Kurven.
Eigenschaften der Normalverteilung
- Sie ist symmetrisch
Die Normalverteilung ist perfekt symmetrisch, d.h. die Verteilungskurve kann in der Mitte, entlang des Mittelwerts, gefaltet werden, um zwei identische Hälften zu erzeugen. Diese symmetrische Form ist das Ergebnis davon, dass die Hälfte der Beobachtungen auf jeder Seite der Kurve fallen. - Der Mittelwert, der Median und der Modus sind alle gleich
Da die Normalverteilung symmetrisch ist, stellt ihr Zentrum den Durchschnitt oder Mittelwert aller Datenpunkte dar. Das bedeutet, dass ihr Median (der Wert in der Mitte eines Satzes, wenn seine Werte von klein nach groß geordnet sind) auch im Zentrum der Verteilung liegt und dem Mittelwert gleich ist. Der Gipfel, der höchste Punkt der Normalverteilungskurve, befindet sich auch in der Mitte des Graphen, was bedeutet, dass der Modus der Verteilung, ihr am häufigsten vorkommender Wert und daher der höchste Punkt auf dem Graphen, ebenfalls im Zentrum der Verteilung liegt. Diese Daten der Normalverteilung repräsentieren die Datenpunkte (Werte), die vorkommen. - Die empirische Regel
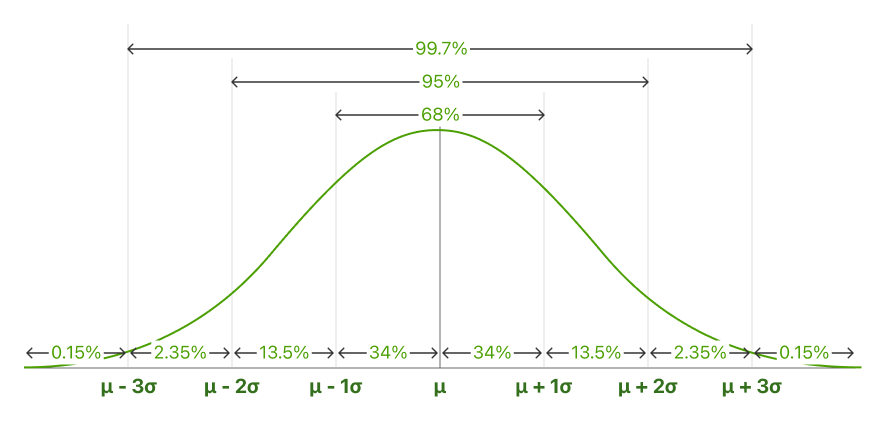
Auch bekannt als die 68-95-99.7 Regel. Die empirische Regel beschreibt den Prozentsatz der Daten, die innerhalb bestimmter Standardabweichungen vom Mittelwert für glockenförmige Kurven fallen.
In normal verteilten Daten liegt ein konstanter Anteil der Strecke unter der Kurve zwischen dem Mittelwert und einer bestimmten Anzahl von Standardabweichungen vom Mittelwert. Die empirische Regel erlaubt es Ihnen, den Anteil der Werte zu bestimmen, die innerhalb bestimmter Entfernungen vom Mittelwert liegen.
68,25% aller Fälle liegen innerhalb von +/- einer Standardabweichung vom Mittelwert.
95% aller Fälle liegen innerhalb von +/- zwei Standardabweichungen vom Mittelwert.
99,7% aller Fälle liegen innerhalb von +/- drei Standardabweichungen vom Mittelwert.
Standard-Normalverteilung
Die Standard-Normalverteilung ist ein Spezialfall der Normalverteilung, bei dem der Mittelwert null und die Standardabweichung eins ist. Diese Verteilung wird auch als Z-Verteilung bezeichnet.
Notationen
- ist der "z-Wert" (Standardwert) - z-Wert bedeutet, wie viele Standardabweichungen ein Wert vom Mittelwert entfernt ist.
- (Mu) ist der Mittelwert.
- (Sigma) ist die Standardabweichung.
Standardwerte
Ein Wert auf der Standard-Normalverteilung wird als Standardwert oder z-Wert bezeichnet. Er stellt die Anzahl der Standardabweichungen oberhalb oder unterhalb des Mittelwerts dar, in die eine bestimmte Beobachtung fällt.
Zum Beispiel zeigt ein Standardwert von an, dass die Beobachtung Standardabweichungen oberhalb des Mittelwerts liegt. Ein negativer Standardwert repräsentiert einen Wert unter dem Durchschnitt. Der Mittelwert hat einen z-Wert von .
Mehr als 99,9% aller Fälle fallen innerhalb von +/- 3,9 Standardabweichungen vom Mittelwert. Daher betrachten wir die Wahrscheinlichkeit aller Daten mit einem z-Wert, der größer als oder kleiner als ist, als 0%. Mit anderen Worten betrachten wir das Intervall zwischen und als 100% der Standard-Normalverteilung.
Bereiche unter der Kurve einer Standard-Normalverteilung finden
Die Normalverteilung ist eine Wahrscheinlichkeitsverteilung. Wie bei jeder Wahrscheinlichkeitsverteilung gibt der Anteil der Fläche, der unter der Kurve zwischen zwei Punkten auf einem Wahrscheinlichkeitsverteilungsdiagramm liegt, die Wahrscheinlichkeit an, dass ein Wert innerhalb dieses Intervalls fällt.
Die Fläche unter der Kurve beträgt , das entspricht 100% der Verteilung. =100%.
Wenn Sie einen z-Wert haben, können Sie den Bereich bis zu diesem Wert finden, indem Sie in einer Tabelle der Standard-Normalverteilung nachsehen. Auch bekannt als die z-Werte Tabelle. (Der Link zur Tabelle folgt in Kürze)
Da die Z-Werte-Tabelle den Bereich bis zum z-Wert anzeigt, wenn Sie die Wahrscheinlichkeit von Daten mit größeren z-Werten finden möchten, müssen Sie die Zahl aus der Tabelle von abziehen. Dies kann als Regel dargestellt werden:
Wenn wir den perfekten z-Wert in der Tabelle nicht finden, wählen wir den nächstgelegenen. Wenn die beiden nächsten z-Werte den gleichen Abstand zu unserem gewünschten z-Wert haben, berechnen wir ihren Durchschnitt.
Weitere Beispiele
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der größer als ist?
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der kleiner als ist?
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der zwischen und liegt?
- Was ist die Wahrscheinlichkeit von Daten mit einem z-Wert, der größer als und kleiner als ist?
Standardisierung
Berechnung der z-Werte
Standardwerte sind ein hervorragendes Mittel, um zu verstehen, wo eine bestimmte Beobachtung im Verhältnis zur gesamten Normalverteilung liegt. Sie ermöglichen es Ihnen auch, Beobachtungen aus normalverteilten Populationen mit unterschiedlichen Mittelwerten und Standardabweichungen zu sammeln und sie auf eine Standard-Skala zu setzen. Nach der Standardisierung Ihrer Daten können Sie sie innerhalb der Standard-Normalverteilung platzieren.
Auf diese Weise ermöglicht die Standardisierung den Vergleich verschiedener Beobachtungen, basierend darauf, wo jede Beobachtung innerhalb ihrer eigenen Verteilung liegt.
Um den Standardwert für eine Beobachtung zu berechnen, nehmen Sie die rohe Messung, subtrahieren den Mittelwert und teilen durch die Standardabweichung. Mathematisch lautet die Formel für diesen Prozess wie folgt:
stellt den Rohwert der interessierenden Messung dar. Es handelt sich dabei um den zu standardisierenden Wert - manchmal auch Datenpunkt genannt.
(Mu) und (Sigma) repräsentieren die Parameter der Population, aus der die Beobachtung stammt.
Weitere verwandte Begriffe
Schiefe
Die Schiefe bezieht sich auf eine Verzerrung oder Asymmetrie, die von der symmetrischen Glockenkurve, oder Normalverteilung, in einer Datenmenge abweicht. Wenn die Kurve nach links oder rechts verschoben ist, spricht man von einer Schiefe. Die Schiefe kann quantifiziert werden als Darstellung des Ausmaßes, in dem eine gegebene Verteilung von einer Normalverteilung abweicht. Die Schiefe unterscheidet extreme Werte in einem gegenüber dem anderen Schwanz. Eine Normalverteilung hat eine Schiefe von null.
Kurtosis
Die Kurtosis misst extreme Werte in beiden Schwänzen. Verteilungen mit großer Kurtosis weisen Enddaten auf, die die Enden der Normalverteilung übertreffen. Verteilungen mit geringer Kurtosis weisen Enddaten auf, die im Allgemeinen weniger extrem sind als die Enden der Normalverteilung. Die Kurtosis ist ein Maß für das kombinierte Gewicht der Schwänze einer Verteilung im Verhältnis zum Zentrum der Verteilung.